| Home Prev | Next |
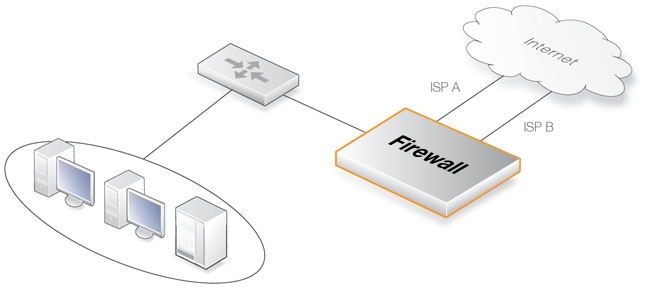
The Route Failover feature is typically used in mission-critical situations where availability and connectivity are crucial. A typical example could be an enterprise where access to the Internet would be disrupted if a single flow to an external Internet Service Provider (ISP) fails. The solution would connectivity to a second ISP with route failover configured to use this second flow if the first fails.
This is illustrated in the diagram below, where there are different Ethernet interfaces and different routes being used to connect to ISP A and ISP B.
The Clavister NetShield Firewall implements route failover through the use of Route Monitoring in which cOS Stream monitors route connectivity by polling external hosts. cOS Stream will then switch traffic to an alternate route should this connectivity appear to be unavailable.
Setting Up Route Failover
To set up route failover, the following steps are required: Route Monitoring must be enabled and this is an option that is enabled on a route by route basis. To enable route failover in a scenario with a preferred and a backup route, the preferred route will have route monitoring enabled, however the backup route does not require this since it will usually have no route to failover to. When route monitoring is enabled for a route, one of the following monitoring methods must be chosen:Decide on the route which requires a route failover if a network failure is detected. This will be sometimes referred to later as the primary route.
Make sure there is an alternate route in the route table to failover to. This route will not be chosen by default because of the value of its Metric property or because it has a wider Network property (cOS Stream will always choose the route with the narrowest fit for the destination IP).
Set up monitoring for the primary route. This can be one of the following two types:
Gateway Monitoring
If the Gateway property has been specified as the next router hop for the route, accessibility to that gateway can be monitored by sending periodic IPv4 ARP or IPv6 ND messages (depending on if it is an IPv4 or IPv6 route being monitored). As long as the gateway responds to these requests, the route is considered to be functioning correctly.
Gateway monitoring is the quickest and easiest way for the administrator to set up monitoring and is described further in Section 6.3.2, Gateway Monitoring.
Host Monitoring
An alternative is to monitor the accessibility of one or more nominated hosts. These hosts might have known availability and polling them can indicate if traffic from the local Clavister NetShield Firewall is reaching them. Host monitoring also provides a way to measure the network delays in reaching remote hosts and to initiate failover to an alternate route if delays exceed administrator specified thresholds.
A detailed discussion of host monitoring can be found in Section 6.3.3, Host Monitoring.
If the enabled monitoring method detects a connectivity failure, the route will be disabled and cOS Stream will search for an alternate route in the routing table.
Route Failover Processing
Once route monitoring is enabled, the processing steps are the following:For every route with monitoring enabled, the designated host or hosts are monitored by polling.
Should monitoring indicate a problem with connectivity, the route is marked as disabled.
The system searches for an alternative route for the destination IP address. If one is found, that route is used for the traffic flow. If one is not found, traffic cannot flow.
The monitoring for the original route will continue even if the route is disabled. If monitoring indicates that connectivity is restored, the route will be re-enabled and used instead of the alternate route.
A restart will also cause a disabled route to be re-enabled. It can then be disabled if monitoring still indicates a connectivity problem.
Route failover processing is discussed further in Section 6.3.4, Route Monitoring Issues.
Gateway Monitoring is Simplified Host Monitoring
The idea with gateway monitoring is to provide a quick and easy way to enable host monitoring. Instead, gateway monitoring simplifies the process by requiring that only two Route object properties be set:MonitorGateway
When enabled, this will set up host monitoring to the IP address value specified by the Gateway property of the Route object. If the Gateway has not been set then setting MonitorGateway has no effect. By default, gateway monitoring is disabled. cOS Stream will use a predefined set of host monitoring settings that cannot be altered by the administrator. It will use the ARP/ND polling method.
The following command will enable gateway monitoring for the second route (index=2) in the main routing table:
System:/>cc RoutingTable main System:/RoutingTable/main> set Route 2 RouteMonitor=Yes MonitorGateway=Yes System:/RoutingTable/main> ccSystem:/>
The property RouteMonitor must always be enabled as well for both gateway monitoring and host monitoring.
GatewayMonitorInterval
The time in milliseconds between each poll. This is the only gateway polling variable that can be set and it can be set in one of two ways. It can be set globally:
System:/> set Settings RoutingSettings GatewayMonitorInterval=100Alternatively, it can be set just on the route itself:
System:/>cc RoutingTable main System:/RoutingTable/main> set Route 2 GatewayMonitorInterval=100 System:/RoutingTable/main> ccSystem:/>
The command above assumes that the route being changed is the second one (index=2) in the routing table main.
Gateway polling and host monitoring can be enabled at the same time. Gateway monitoring could be also be set up by the administrator using host monitoring but if there is a requirement to have precise control over all the configurable options.
Overview
To provide a more flexible and configurable way to monitor the integrity of routes, cOS Stream provides the additional capability to perform Host Monitoring. This feature means that one or more external host systems can be routinely polled to check that a particular route is available.The advantages of host monitoring are twofold:
In a complex network topology it is more reliable to check accessibility to external hosts. Just monitoring a link to a local switch may not indicate a problem in another part of the internal network.
Host monitoring can be used to help in setting the acceptable Quality of Service level of Internet response times. Internet access may be functioning but it may be desirable to instigate route failover if response latency times become unacceptable using the existing route.
Enabling Host Monitoring
Enabling host monitoring requires the following steps:The RouteMonitor property of a Route object must be set to Yes. This is a prerequisite for either enabling gateway monitoring or host monitoring.
The MonitorHosts property of the same Route object must be set to Yes. This can be done in the same CLI command as the previous step.
One or more MonitorHost objects are added as children to the Route object. Each MonitorHost object specifies a single host to monitor and the monitoring settings for that host. Multiple hosts can provide a higher certainty that any network problem resides in the local network rather than because a single remote host is unreachable.
Settings in the Route Object
For host monitoring there are the following related properties for a Route object:GracePeriod
This is the period of time in seconds after startup or after reconfiguration of the Clavister NetShield Firewall which cOS Stream will wait before starting Route Monitoring. This waiting period allows time for all network links to initialize once the firewall comes online.
MinReachability
This is the minimum number of hosts that must be considered to be accessible before the route is deemed to have failed. The criteria for host accessibility are described below.
GratuitousARPOnChange setting
Send a gratuitous ARP or ND (depending on if the route is for IPv4 or IPv6) on the alternate route's interface to alert connected equipment of changes to MAC addresses and associated IP addresses. This is enabled by default and must be enabled for the alternate Route object.
Settings in the MonitoredHost Object
For each MonitoredHost object added to a Route object, there are a number of properties that should be set:MonitoringMethod
The method by which the host is to be polled. Currently, this can be:
ICMP - Polling using ICMP "Ping" messages. An IP address must be specified for this method and hosts must be configured to reply to such messages.
ARP/ND - This is used only for hosts that are on the same network as the Clavister NetShield Firewall. It works by sending either an IPv4 ARP query or an IPv6 Neighbor Discovery message to the host specified by the IP address. Which one is sent depends on the IP address type of the Route object's Network property.
IPAddress
The IP address of the host when using the ICMP option. This will be either an IPv4 or an IPv6 address and this should agree with if the route is for an IPv4 or IPv6 network range.
OriginatorIP
The source IP address used when polling a host. If not specified, the LocalIP property of the Route object will be used and if that is not set then the IP address of the sending interface IP will be used.
Whichever source IP is used, its IP type (either IPv4 or IPv6) must agree with the IP type of the Network property of the Route object.
HostMonitorInterval
The interval in milliseconds between polling attempts. The default setting is 1000 milliseconds and the minimum value allowed is 10 milliseconds.
Samples
The number of polling attempts used as a sample size for calculating the Percentage Loss and the Average Latency. This value cannot be less than 1. The default value is 10.
MaxFailedSamples
The maximum permissible number of polling attempts that fail. If this number is exceeded then the host is considered unreachable. The default value is 2.
MaxLatency
The maximum number of milliseconds allowable between a poll request and the response. If this threshold is exceeded then the host is considered unreachable. Average Latency is calculated by averaging the response times from the host. If a polling attempt receives no response then it is not included in the averaging calculation.
ReachabilityRequired
When this is selected, the host must be determined as accessible in order for that route to be considered to be functioning. Even if other hosts are accessible, this option says that the accessibility of a host with this option set is mandatory.
Where multiple hosts are specified for host monitoring, more than one of them could have Reachability Required enabled. If cOS Stream determines that any host with this option enabled is not reachable, Route Failover is initiated.
Example 6.4. Setting Up Route Monitoring
This example will add route monitoring to the second route (index=2) in the main routing table. The monitoring will consist of polling two hosts on the same network. One host will be polled with ICMP and the other with ARP. If one host will not respond to ICMP because it is wrongly configured then we can check the other host's availability with ARP.
Change the CLI context to the main routing table.
System:/> cc RoutingTable main
Enable host monitoring:
System:/RoutingTable/main> set Route 2 RouteMonitor=Yes MonitorHosts=Yes
Change the CLI context to be the second route in the table:
System:/RoutingTable/main> cc Route 2
Add the first host monitor to the route which polls a host on the same network using ARP. The host is considered unreachable if 5 out of 15 attempts fails:
System:/RoutingTable/main/Route/2> add MonitoredHost
MonitoringMethod=ARP/ND
IPAddress=203.0.113.8
Samples=15
MaxFailedSamples=5
Add a second host monitor to the route which polls a remote host using ICMP (the default method). This host must be reachable:
System:/RoutingTable/main/Route/2> add MonitoredHost
IPAddress=203.0.113.5
ReachabilityRequired=Yes
Return to the original CLI context:
System:/RoutingTable/main> cc
System:/>
This section will discuss various issues that should be considered when setting up route monitoring.
Any Automatically Added Routes Will Need Redefining
It is important to note that route monitoring cannot be enabled on automatically added routes. For example, the routes that cOS Stream creates at initial startup for physical interfaces (these are known as core routes) are such automatically added routes. Routes added automatically during IPsec tunnel setup are also of this type.The reason why monitoring cannot be enabled for these routes is because automatically created routes have a special status in a configuration and are treated differently. If route monitoring is required on an automatically created route, the original route should first be deleted and then it should be recreated manually as a new route. Monitoring can then be enabled on this newly created route.
Setting the Route Metric
When specifying routes, the administrator should manually set a route's Metric property. The metric is a positive integer that indicates how preferred the route is as a means to reach its destination. When two routes offer a means to reach the same destination, cOS Stream will select the one with the lowest metric value for sending data (if two routes have the same metric, the route found first in the routing table will be chosen).A primary, preferred route should have a lower metric (for example "10"), and a secondary, failover route should have a higher metric value (for example "20").
Multiple Failover Routes
It is possible to specify more than one failover route. For instance, the primary route could have two other routes as failover routes instead of just one. In this case the metric should be different for each of the three routes: "10" for the primary route, "20" for the first failover route and "30" for the second failover route. The first two routes would have route monitoring enabled in the routing table but the last one (with the highest metric) would not since it has no route to failover to.Failover Processing
Whenever monitoring determines that a route is not available, cOS Stream will mark the route as disabled and instigate route failover for existing and new flows. For already established flows, a route lookup will be performed to find the next best matching route and the flows will then switch to using the new route. For new flows, route lookup will ignore disabled routes and the next best matching route will be used instead.The table below defines two default routes, both having all-nets as the destination, but using two different gateways. The first, primary route has the lowest metric and also has route monitoring enabled. Route monitoring for the second, alternate route is not meaningful since it has no failover route.
| Route # | Interface | Destination | Gateway | Metric | Monitoring |
|---|---|---|---|---|---|
| 1 | wan | all-nets | 195.66.77.1 | 10 | On |
| 2 | wan | all-nets | 193.54.68.1 | 20 | Off |
When a new flow is about to be established to a host on the Internet, a route lookup will result in the route that has the lowest metric being chosen. If the primary WAN router should then fail, this will be detected by cOS Stream, and the first route will be disabled. As a consequence, a new route lookup will be performed and the second route will be selected with the first one being marked as disabled.
Re-enabling Routes
Even if a route has been disabled, cOS Stream will continue to check the status of that route. Should the route become available again, it will be re-enabled and existing flows will automatically be transferred back to it.Route Interface Grouping
When using route monitoring, it is important to check if a failover to another route will cause the routing interface to be changed. If this could happen, it is necessary to take some precautionary steps to ensure that policies and existing flows will be maintained.To illustrate the problem, consider the following configuration:
First, there is one IP rule that will NAT all HTTP traffic destined for the Internet through the wan interface:
| Action | Src Iface | Src Net | Dest Iface | Dest Net | Parameters |
|---|---|---|---|---|---|
| NAT | if1 | if1_net | wan | all-nets | http |
The routing table consequently contains the following default route:
| Interface | Destination | Gateway | Metric | Monitoring |
|---|---|---|---|---|
| wan | all-nets | 203.0.113.1 | 10 | Off |
Now a secondary route is added over a backup DSL connection and Route Monitoring is enabled for this. The updated routing table will look like this:
| Route # | Interface | Destination | Gateway | Metric | Monitoring |
|---|---|---|---|---|---|
| 1 | wan | all-nets | 203.0.113.1 | 10 | On |
| 2 | dsl | all-nets | 198.51.100.1 | 20 | Off |
Notice that route monitoring is enabled for the first route but not the backup, failover route.
As long as the preferred wan route is healthy, everything will work as expected. Route monitoring will also be functioning, so the secondary route will be enabled if the wan route should fail.
There are, however, some problems with this setup: if a route failover occurs, the default route will then use the dsl interface. When a new HTTP flow is then established from the intnet network, a route lookup will be made resulting in a destination interface of dsl. The IP rules will then be evaluated, but the original NAT rule assumes the destination interface to be wan so the new flow will be dropped by the rule set.
In addition, any existing flows matching the NAT rule will also be dropped as a result of the change in the destination interface. Clearly, this is undesirable.
To overcome this issue, potential destination interfaces should be grouped together into an InterfaceGroup object and the SecurityEquivalentInterfaces property of each interface should be set to the other interfaces in the group (see Section 3.6, Security/Transport Equivalence for more on this topic). This InterfaceGroup object will then used as the destination interface in IP rules. For more information on groups, see Section 3.4, Interface Groups.